בסיס ידע
נתיב: /dashboard/ (טאב Data) · הרשאה: מודול Knowledge Base
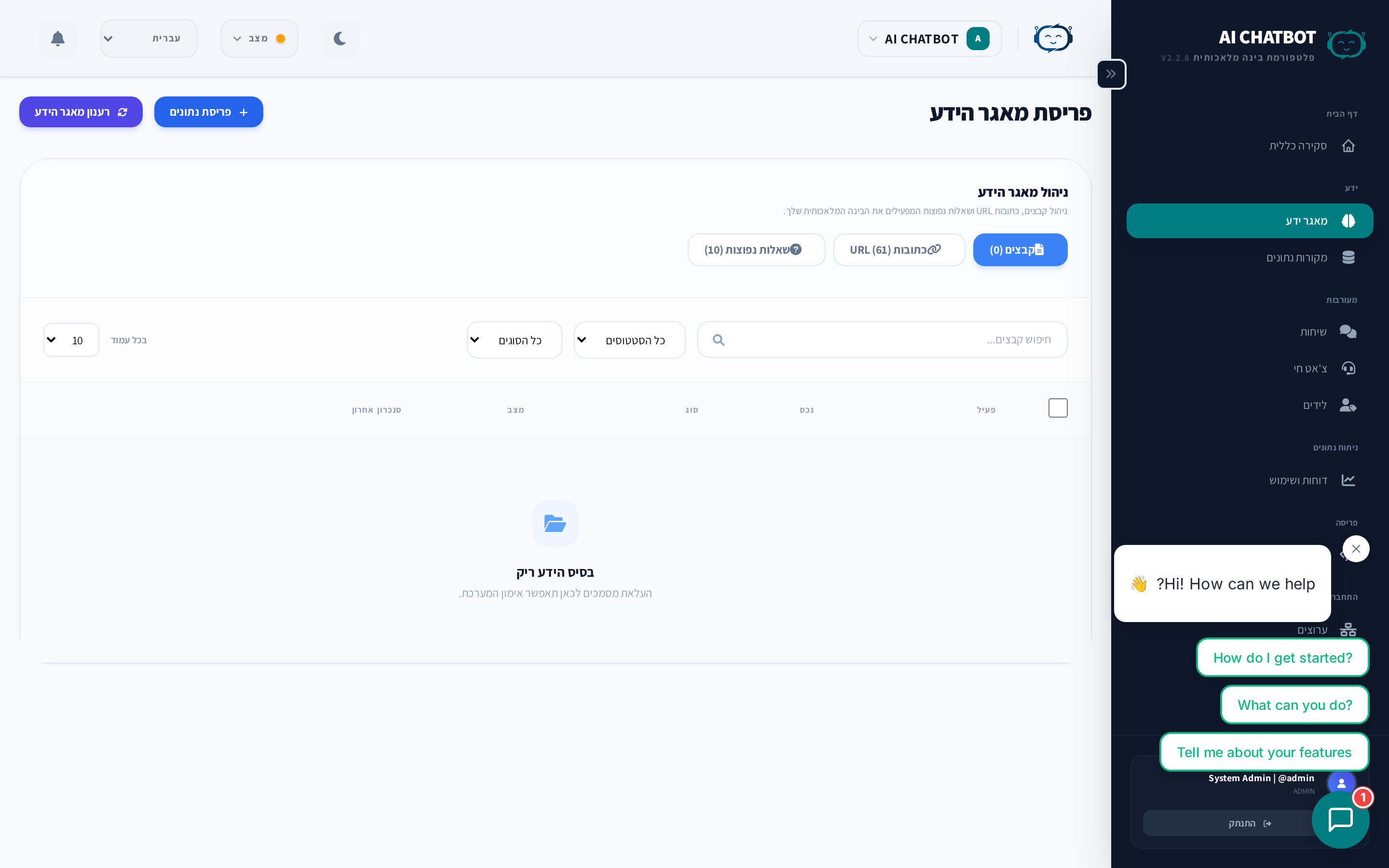
בסיס הידע הוא המקום שבו אתה מאמן את עוזר ה-AI שלך. הוא מגדיר מה הבוט יודע ועל מה הוא יכול לענות באמצעות המסמכים, דפי האינטרנט ושאלות התשובות שלך. כל מה שאתה מעלה עובר אינדקס למנוע חיפוש וקטורי כך שהבוט יכול לחפש לפי משמעות - לא רק מילות מפתח. זה הבסיס לאינטליגנציה של הבוט שלך.
איך עובד חיפוש וקטורי
בניגוד לחיפוש מילות מפתח מסורתי, FRENZY.BOT משתמש בחיפוש סמנטי (נקרא גם חיפוש וקטורי). המשמעות:
- משתמש ששואל "מה המחיר?" יקבל התאמה למסמך על "תכניות תמחור" - גם אם המילים המדויקות שונות.
- המערכת מבינה משמעות, לא רק מילות מפתח.
- כל פיסת תוכן מומרת ל-"embedding" מספרי שלוכד את המשמעות שלה.
- כשמשתמש שואל שאלה, המערכת מוצאת את התוכן הכי דומה סמנטית ושולחת אותו למודל ה-AI ליצירת תשובה.
בגלל זה איכות התוכן בבסיס הידע שלך קובעת ישירות את איכות התשובות של הבוט.
קבצים
העלה מסמכים פנימיים ישירות לבסיס הידע של הבוט שלך.
פורמטים נתמכים
| פורמט | מתאים ל |
|---|---|
| מדיניות, דוחות, דפי מוצר (השתמש ב-PDFs מבוססי טקסט, לא תמונות סרוקות) | |
| DOCX | מסמכים פנימיים, נהלים, מדריכים |
| TXT | תוכן טקסט פשוט, לוגים, הערות |
| CSV | נתונים מובנים, טבלאות מחירים, רשימות מוצרים |
| JSON | תיעוד API, נתוני קונפיגורציה |
| Markdown | תיעוד טכני, קבצי README |
| PPTX | מצגות עם תוכן טקסטואלי |
שלב אחר שלב: העלאת קובץ
- עבור ל-Knowledge Base → Files.
- גרור קבצים לאזור ההעלאה או לחץ על Upload.
- המתן שמחוון הסטטוס יציג Live.
- שאל את הבוט שאלה מהקובץ הזה כדי לאמת שהוא למד את התוכן.
ניהול קבצים
- Enable/disable — הפעל/השבת קבצים בודדים בלי למחוק אותם.
- Preview — צפה בטקסט המחולץ כדי לוודא איכות תוכן.
- Delete — הסר מסמכים מיושנים (מוחק גם מהאינדקס הוקטורי).
- Batch operations — בחר מספר קבצים לפעולות מרובות.
גודל קבצים ומגבלות
| מגבלה | ערך |
|---|---|
| גודל קובץ מקסימלי | 50 MB לקובץ |
| גודל קובץ מומלץ | מתחת ל-10 MB לעיבוד מהיר ביותר |
| מספר קבצים | אין מגבלה קשיחה — תלוי במשאבי השרת |
| זמן עיבוד | 10-60 שניות לקובץ; PDFs גדולים עשויים לקחת מספר דקות |
שיטות עבודה מומלצות
- השתמש ב-PDFs נקיים ומבוססי טקסט. PDFs של תמונות סרוקות בלי טקסט שאפשר לבחור יתנו תוצאות גרועות. אם יש לך רק PDFs סרוקים, העבר אותם דרך תוכנת OCR קודם.
- תן שמות תיאוריים לקבצים (לדוגמה,
pricing_2026.pdf,return_policy_v3.docx) — זה עוזר לך לזהות תוכן אחר כך. - פצל מסמכים גדולים לקבצים קטנים יותר לאינדקס מהיר יותר ואחזור מדויק יותר. מדריך של 200 עמודים צריך להיות מפוצל לפרקים.
- הסר תוכן מיושן כדי למנוע מהבוט לתת תשובות לא עדכניות. דפי מחירים ישנים או מדיניות שפג תוקפה הם החשודים הרגילים.
- סקור את הטקסט המחולץ — השתמש בפיצ'ר ה-Preview כדי לוודא שהמערכת חילצה נכון את הטקסט מהקובץ שלך.
URLs
למד את הבוט ישירות מדפי אינטרנט ציבוריים. המערכת מושכת כל דף, מסירה ניווט, תפריטים וסקריפטים, ומאנדקסת רק את התוכן הקריא.
מצבי URL
- Single page — הוסף URL אחד בכל פעם לדפים ספציפיים.
- Sitemap — ספק URL של
sitemap.xmlכדי לגלות ולייבא את כל הדפים מאתר.
שלב אחר שלב: הוספת URL
- עבור ל-Knowledge Base → URLs.
- הדבק URL ציבורי (חייב להיות
http://אוhttps://). - לחץ על Add URL.
- עקוב אחרי הסטטוס: Pending → Processing → Live.
ניהול Crawl
- מעקב סטטוס — כל URL מציג את המצב הנוכחי שלו (Live / Processing / Error).
- Re-crawl — הרץ מחדש crawls כשתוכן האתר שלך משתנה כדי לשמור את הבוט מעודכן.
- טיפול בשגיאות — אם URL נכשל, בדוק אם האתר חוסם בוטים או דורש אימות.
טיפים ל-URLs
- רק דפים ציבוריים. דפים מאחורי קירות התחברות ייכשלו באינדקס.
- ייבוא Sitemap היא הדרך המהירה ביותר לאנדקס אתר שלם בבת אחת.
- חלק מהאתרים חוסמים crawlers. אם URL מציג שגיאה, נסה לספק את התוכן כקובץ במקום.
- אתרים עם הרבה JavaScript (SPAs) עשויים להחזיר תוכן ריק. אם URL לא מציג טקסט אחרי אינדקס, הורד את תוכן הדף והעלה כקובץ.
- Re-crawl באופן קבוע אם תוכן האתר שלך משתנה לעתים קרובות — הגדר תזכורת לרענן חודשית.
Data Sources
נתיב: /dashboard/data-sources
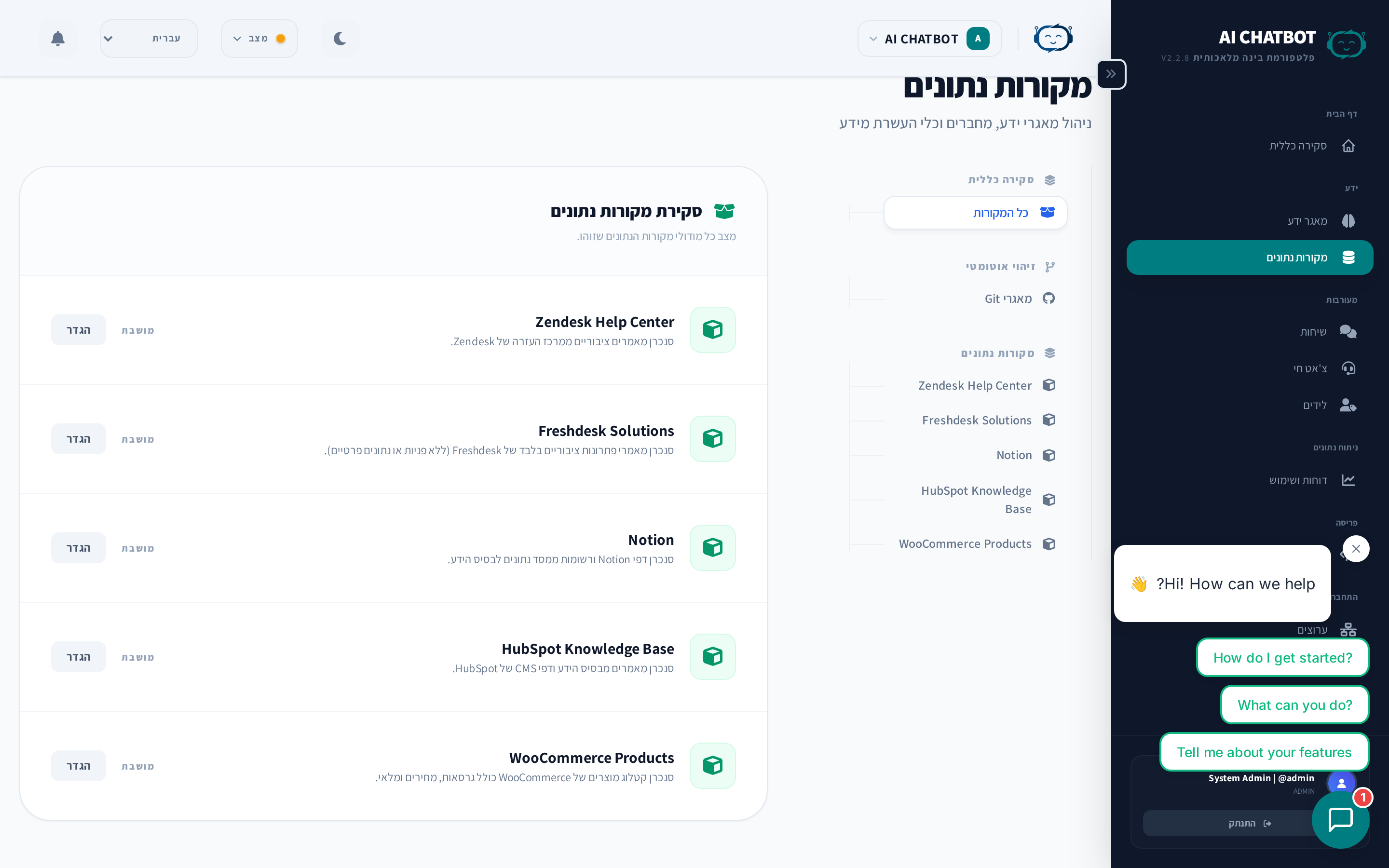
דף ה-Data Sources מספק סקירה של כל מקורות התוכן המזינים את בסיס הידע שלך. הוא מציג:
| עמודה | מה זה מציג |
|---|---|
| Source | שם קובץ, URL, או מזהה FAQ |
| Type | File, URL, או FAQ |
| Status | Live (ניתן לחיפוש), Processing, Error, או Disabled |
| Size | גודל תוכן או מספר chunks באינדקס |
| Last Updated | מתי המקור עבר אינדקס או re-crawl לאחרונה |
סנכרון WordPress
אם האתר שלך רץ על WordPress, FRENZY.BOT יכול לסנכרן אוטומטית תוכן מאתר ה-WordPress שלך:
- עבור ל-Data Sources או Knowledge Base → URLs.
- הוסף את ה-
sitemap.xmlURL של אתר ה-WordPress שלך (בדרך כללhttps://yoursite.com/sitemap.xml). - המערכת מגלה ומאנדקסת את כל הדפים והפוסטים שפורסמו.
- כשאתה מפרסם תוכן חדש ב-WordPress, תריץ re-crawl של ה-sitemap כדי לשמור את הבוט מעודכן.
שמור את הבוט שלך מסונכרן עם האתר
אחרי פרסום פוסטים חדשים או עדכון דפי מוצר, לחץ על Refresh Knowledge Base כדי לבצע re-index של הכל. זה מבטיח שלבוט תמיד יהיה התוכן העדכני ביותר שלך.
FAQs
הוסף תשובות מדויקות לשאלות בעדיפות הגבוהה ביותר שלך. FAQs נותנים לך שליטה מלאה על תשובות ספציפיות.
למה FAQs חזקים
- תשובות בעדיפות — תשובות FAQ מקבלות עדיפות על פני אחזור מבוסס-מסמכים לשאלות תואמות.
- אינדקס מיידי — FAQs זמינים מיד, בלי עיכוב עיבוד.
- שליטה מדויקת — אתה כותב את התשובה המדויקת שהבוט ישתמש בה.
- עדכונים קלים — ערוך או מחק זוגות שאלה-תשובה בודדים בלי להעלות מחדש קבצים.
שלב אחר שלב: הוספת FAQ
- עבור ל-Knowledge Base → FAQs.
- לחץ על Add FAQ.
- הזן את השאלה שהמשתמשים שלך ישאלו.
- הזן את התשובה המדויקת שלך.
- שמור — ה-FAQ חי מיד.
- בדוק בצ'אט כדי לאמת.
מתי להשתמש ב-FAQs
| תרחיש | דוגמה |
|---|---|
| שאלות תמחור | "כמה עולה התוכנית Pro?" → תשובת מחיר מדויקת |
| תשובות מדיניות | "מה מדיניות ההחזרות שלכם?" → טקסט מדיניות רשמי |
| שעות / מידע ליצירת קשר | "מתי אתם פתוחים?" → שעות פעילות |
| התנגדויות נפוצות | "למה אני צריך לבחור בכם ולא ב-X?" → תשובת פוזישן |
| תיקונים | הבוט טועה במשהו → FAQ גובר עם תשובה נכונה |
רענון ידע
לחץ על Refresh Knowledge Base כדי לבצע re-index של כל התוכן. זה בונה מחדש את האינדקס הוקטורי מהקבצים, URLs ו-FAQs הנוכחיים שלך.
מתי לרענן:
- אחרי העלאה או עדכון של קבצים
- אחרי שתוכן האתר השתנה
- אחרי הוספת מספר FAQs בקבוצה
- אחרי הסרת תוכן מיושן
רענון לא הרסני
רענון לא מוחק את תוכן המקור שלך. הוא מעבד מחדש הכל כדי להבטיח שהאינדקס הוקטורי תואם את הנתונים הנוכחיים שלך.
בידוד נתונים לכל בוט
בהתקנת multi-bot, לכל בוט יש vector collection נפרד משלו. המשמעות:
- בסיס הידע של בוט A בלתי נראה לחלוטין לבוט B.
- העלאת קובץ לבוט אחד לא משפיעה על אף בוט אחר.
- מחיקת בוט מסירה את כל ה-vector collection שלו ואת כל הקבצים שהועלו.
- לכל בוט יכול להיות תוכן שונה לחלוטין, מותאם לקהל הספציפי שלו.
FAQ
ש: קובץ מציג סטטוס "Error".
- הקובץ עשוי להיות מושחת, מוגן בסיסמה, או בפורמט לא נתמך. נסה להמיר ל-PDF או DOCX ולהעלות מחדש.
ש: URLs חסומים או מציגים תוכן ריק.
- חלק מהאתרים חוסמים crawlers אוטומטיים. נסה URL אחר, ספק sitemap, או העלה את תוכן הדף כקובץ במקום.
ש: הבוט עונה בצורה לא נכונה על נושא.
- הוסף FAQ עם התשובה הנכונה המדויקת — FAQs מקבלים עדיפות. גם סקור את ה-system prompt ב-Settings → Model Behavior להוראות סותרות.
ש: כמה זמן לוקח אינדקס?
- קבצים: בדרך כלל 10-60 שניות תלוי בגודל. PDFs גדולים או sitemaps עם הרבה דפים יכולים לקחת מספר דקות. עקוב אחרי התקדמות ב-Sync Jobs.
ש: אפשר לאנדקס תוכן מאחורי התחברות?
- לא ישירות. דפים שדורשים אימות ייכשלו. ייצא את התוכן והעלה אותו כקובץ במקום.