Base de Conhecimento
Caminho: /dashboard/ (aba Dados) · Permissão: Módulo Base de Conhecimento
A Base de Conhecimento é onde você treina seu assistente de IA. Ela define o que o bot sabe e o que pode responder usando seus próprios documentos, páginas da web e FAQs selecionadas. Tudo o que você carrega é indexado em um mecanismo de busca vetorial para que o bot possa pesquisar pelo significado — não apenas por palavras-chave. Esta é a base da inteligência do seu bot.
Como funciona a busca vetorial
Ao contrário da busca tradicional por palavras-chave, o FRENZY.BOT utiliza a busca semântica (também chamada de busca vetorial). Isso significa:
- Um usuário perguntando "Qual é o preço?" corresponderá a um documento sobre "planos de tarifação" — mesmo que as palavras exatas sejam diferentes.
- O sistema entende o significado, não apenas as palavras-chave.
- Cada parte do conteúdo é convertida em um "embedding" numérico que captura seu significado.
- Quando um usuário faz uma pergunta, o sistema encontra o conteúdo semanticamente mais semelhante e o envia para o modelo de IA para a geração da resposta.
É por isso que a qualidade do conteúdo da sua base de conhecimento determina diretamente a qualidade das respostas do seu bot.
Arquivos
Faça o upload de documentos internos diretamente para a base de conhecimento do seu bot.
Formatos suportados
| Formato | Ideal para |
|---|---|
| Políticas, relatórios, fichas de produtos (use PDFs baseados em texto, não imagens digitalizadas) | |
| DOCX | Documentos internos, SOPs (procedimentos operacionais), guias |
| TXT | Conteúdo em texto simples, logs, notas |
| CSV | Dados estruturados, tabelas de preços, listas de produtos |
| JSON | Documentação de API, dados de configuração |
| Markdown | Documentos técnicos, arquivos README |
| PPTX | Apresentações com conteúdo de texto |
Passo a passo: Carregar um arquivo
- Vá para Base de Conhecimento → Arquivos.
- Arraste os arquivos para a área de upload ou clique em Upload.
- Aguarde até que o indicador de status mostre Live.
- Faça uma pergunta ao bot baseada nesse arquivo para confirmar que ele aprendeu o conteúdo.
Gerenciamento de arquivos
- Ativar/desativar — Alterne arquivos individuais sem excluí-los.
- Visualizar — Veja o texto extraído para verificar a qualidade do conteúdo.
- Excluir — Remova documentos desatualizados (também remove do índice vetorial).
- Operações em lote — Selecione vários arquivos para ações em massa.
Tamanho de arquivo e limites
| Limite | Valor |
|---|---|
| Tamanho máximo de arquivo | 50 MB por arquivo |
| Tamanho recomendado | Abaixo de 10 MB para processamento mais rápido |
| Número de arquivos | Sem limite rígido — depende dos recursos do servidor |
| Tempo de processamento | 10–60 segundos por arquivo; PDFs grandes podem levar vários minutos |
Melhores práticas
- Use PDFs limpos e baseados em texto. PDFs de imagens digitalizadas sem texto selecionável produzirão resultados insatisfatórios. Se você tiver apenas PDFs digitalizados, passe-os por um software de OCR primeiro.
- Nomeie os arquivos de forma descritiva (ex:
precos_2026.pdf,politica_de_devolucao_v3.docx) — isso ajuda você a identificar o conteúdo mais tarde. - Divida documentos grandes em arquivos menores para uma indexação mais rápida e recuperação mais precisa. Um manual de 200 páginas deve ser dividido em capítulos.
- Remova conteúdo desatualizado para evitar que o bot forneça respostas antigas. Tabelas de preços obsoletas ou políticas expiradas são problemas comuns.
- Revise o texto extraído — Use o recurso de Visualização para verificar se o sistema extraiu corretamente o texto do seu arquivo.
URLs
Ensine seu bot diretamente a partir de páginas públicas da web. O sistema busca cada página, remove a navegação, menus e scripts, e indexa apenas o conteúdo legível.
Modos de URL
- Página única — Adicione uma URL de cada vez para páginas específicas.
- Sitemap — Forneça a URL de um
sitemap.xmlpara descobrir e importar todas as páginas de um site.
Passo a passo: Adicionar uma URL
- Vá para Base de Conhecimento → URLs.
- Cole uma URL pública (deve ser
http://ouhttps://). - Clique em Adicionar URL.
- Monitore o status: Pendente → Processando → Live.
Gerenciamento de rastreamento (Crawl)
- Acompanhamento de status — Cada URL mostra seu estado atual (Live / Processando / Erro).
- Re-rastrear (Re-crawl) — Execute o rastreamento novamente quando o conteúdo do seu site mudar para manter o bot atualizado.
- Tratamento de erros — Se uma URL falhar, verifique se o site bloqueia bots ou requer autenticação.
Dicas para URLs
- Apenas páginas públicas. Páginas protegidas por login não serão indexadas.
- A importação por Sitemap é a maneira mais rápida de indexar um site inteiro de uma vez.
- Alguns sites bloqueiam rastreadores. Se uma URL mostrar erro, tente fornecer o conteúdo como um arquivo.
- Sites com muito JavaScript (SPAs) podem retornar conteúdo vazio. Se uma URL não mostrar texto após a indexação, baixe o conteúdo da página e carregue-o como um arquivo.
- Re-rastreie regularmente se o conteúdo do seu site mudar com frequência — defina um lembrete para atualizar mensalmente.
Fontes de Dados
Caminho: /dashboard/data-sources
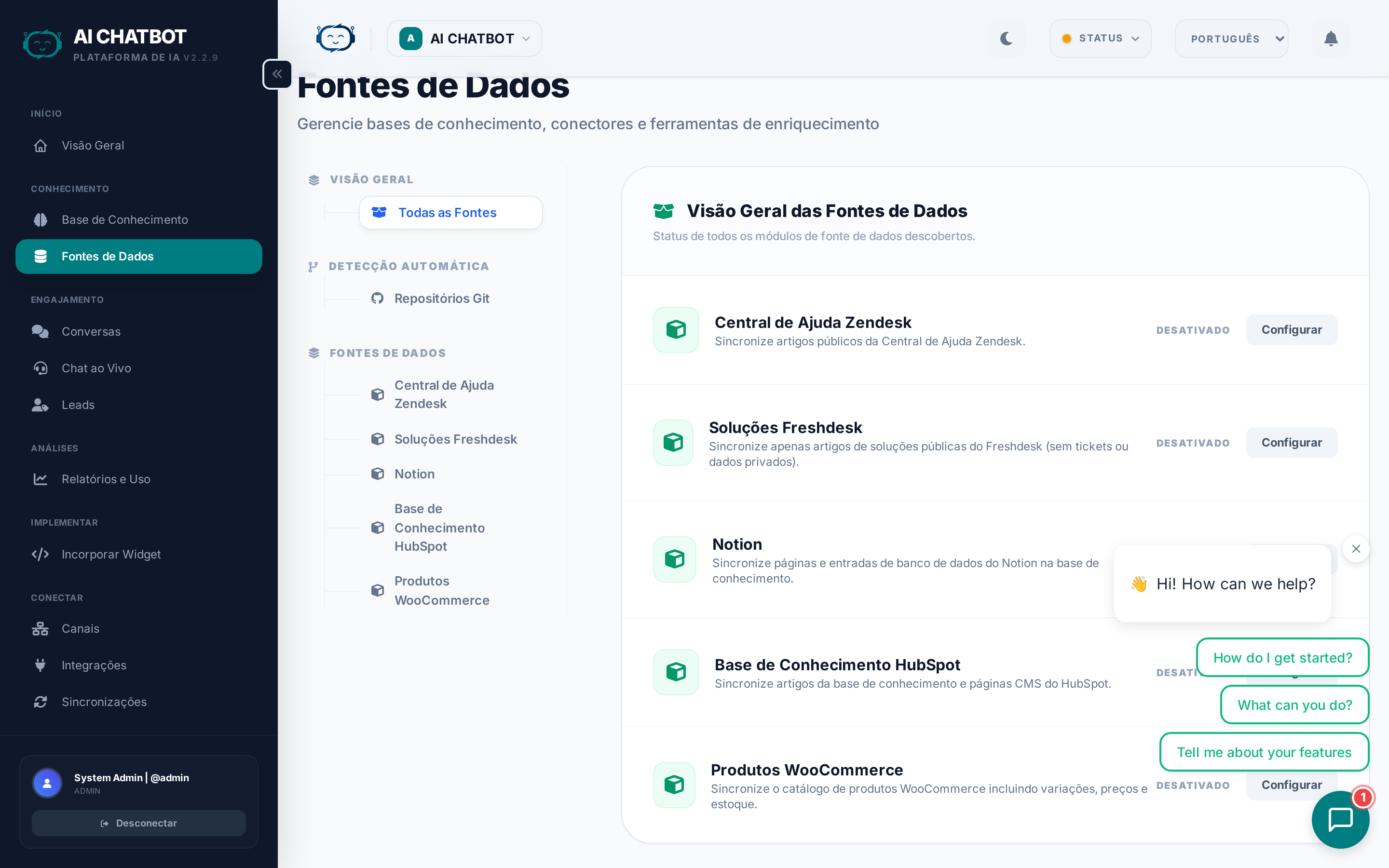
A página de Fontes de Dados fornece uma visão geral de todas as fontes de conteúdo que alimentam sua base de conhecimento. Ela mostra:
| Coluna | O que mostra |
|---|---|
| Fonte | Nome do arquivo, URL ou identificador de FAQ |
| Tipo | Arquivo, URL ou FAQ |
| Status | Live (pesquisável), Processando, Erro ou Desativado |
| Tamanho | Tamanho do conteúdo ou número de blocos (chunks) indexados |
| Última Atualização | Quando a fonte foi indexada ou rastreada pela última vez |
Sincronização com WordPress
Se o seu site utiliza WordPress, o FRENZY.BOT pode sincronizar automaticamente o conteúdo do seu site:
- Vá para Fontes de Dados ou Base de Conhecimento → URLs.
- Adicione a URL do
sitemap.xmldo seu site WordPress (geralmentehttps://seusite.com/sitemap.xml). - O sistema descobre e indexa todas as páginas e posts publicados.
- Quando você publicar novo conteúdo no WordPress, re-rastreie o sitemap para manter o bot atualizado.
Mantenha seu bot em sincronia com seu site
Após publicar novos posts no blog ou atualizar páginas de produtos, clique em Refresh Knowledge Base para reindexar tudo. Isso garante que o bot sempre tenha seu conteúdo mais recente.
FAQs
Adicione respostas exatas para suas perguntas de maior prioridade. As FAQs oferecem controle total sobre respostas específicas.
Por que as FAQs são poderosas
- Respostas prioritárias — As respostas de FAQ têm precedência sobre a recuperação baseada em documentos para perguntas correspondentes.
- Indexação instantânea — As FAQs ficam disponíveis imediatamente, sem atraso de processamento.
- Controle preciso — Você escreve a resposta exata que o bot usará.
- Atualizações fáceis — Edite ou exclua pares de Pergunta e Resposta individuais sem precisar carregar arquivos novamente.
Passo a passo: Adicionar uma FAQ
- Vá para Base de Conhecimento → FAQs.
- Clique em Adicionar FAQ.
- Digite a pergunta que seus usuários fariam.
- Digite sua resposta exata.
- Salve — a FAQ entra no ar imediatamente.
- Teste no chat para verificar.
Quando usar FAQs
| Cenário | Exemplo |
|---|---|
| Perguntas sobre preços | "Quanto custa o plano Pro?" → Resposta com preço exato |
| Respostas sobre políticas | "Qual é a política de devolução?" → Texto oficial da política |
| Horários / Contato | "Quando vocês estão abertos?" → Horário de funcionamento |
| Objeções comuns | "Por que devo escolher vocês em vez da Empresa X?" → Resposta de posicionamento |
| Correções | O bot errou algo → A FAQ substitui pela resposta correta |
Atualizando o conhecimento
Clique em Refresh Knowledge Base para reindexar todo o conteúdo. Isso reconstrói o índice vetorial a partir de seus arquivos, URLs e FAQs atuais.
Quando atualizar:
- Após carregar ou atualizar arquivos.
- Após o conteúdo do site ter mudado.
- Após adicionar várias FAQs em lote.
- Após remover conteúdo desatualizado.
A atualização não é destrutiva
A atualização não exclui seu conteúdo de origem. Ela reprocessa tudo para garantir que o índice vetorial corresponda aos seus dados atuais.
Isolamento de dados por bot
Em uma configuração multi-bot, cada bot possui sua própria coleção vetorial separada. Isso significa que:
- A base de conhecimento do Bot A é completamente invisível para o Bot B.
- Carregar um arquivo em um bot não afeta nenhum outro bot.
- Excluir um bot remove toda a sua coleção vetorial e todos os arquivos carregados.
- Cada bot pode ter conteúdos completamente diferentes, otimizados para seu público específico.
FAQ (Perguntas Frequentes)
P: Um arquivo mostra o status "Erro".
- O arquivo pode estar corrompido, protegido por senha ou em um formato não suportado. Tente converter para PDF ou DOCX e carregue novamente.
P: As URLs estão bloqueadas ou mostram conteúdo vazio.
- Alguns sites bloqueiam rastreadores automáticos. Tente uma URL diferente, forneça um sitemap ou carregue o conteúdo da página como um arquivo.
P: O bot responde incorretamente sobre um tópico.
- Adicione uma FAQ com a resposta correta exata — as FAQs têm prioridade. Além disso, revise o prompt do sistema em Configurações → Comportamento do Modelo para verificar instruções conflitantes.
P: Quanto tempo leva a indexação?
- Arquivos: normalmente 10-60 segundos, dependendo do tamanho. PDFs grandes ou sitemaps com muitas páginas podem levar vários minutos. Monitore o progresso em Trabalhos de Sincronização.
P: Posso indexar conteúdo atrás de um login?
- Não diretamente. Páginas que exigem autenticação falharão. Exporte o conteúdo e carregue-o como um arquivo.